Exam takers are aware of the linguistic and other difficulties associated with providing paragraph-length answers for open-ended questions. This is in contrast to simple yes/no questions or multiple-choice questions. Long-form questions-answering (LFQA), presents similar challenges to the natural language processing research field (NLP). Existing approaches tend to focus only on two core tasks: information retrieval, and synthesis.
In the new paper WebGPT: Browser-assisted question-answering with Human FeedbackOpenAI’s research team combines these methods with new training objectives. They use the Microsoft Bing Web Search API to retrieve documents and unsupervised pretraining. Human feedback is used to optimize answer quality. This allows them to achieve human-level performance for LFQA tasks.

Here are the key contributions of the team:
- We create a text based web-browsing environment with which a fine-tuned language modeling can interact. This allows us to improve retrieval and synthesis in an integrated fashion by general methods like reinforcement learning and imitation learning.
- References are the passages that are extracted from web pages by the model to generate answers. This is critical for labellers to be able to assess the factual accuracy and validity of answers without engaging in subjective research.

Modern search engines can provide up-to-date information and are fast. This has made search engines more popular for people searching for answers to common questions. The number of searches we do daily on the internet is estimated to be in the billions. OpenAI researchers therefore set out to design a text based web-browsing environment to allow pretrained language models mimic human web search behaviour.
The WebGPT model proposes web-based actions, such as clicking links, scrolling through pages, extracting quotes and references, running a Bing search and clicking on hyperlinks. The browsing continues until the model issues an instruction to end browsing. Finally, if the model has found at least one relevant source, it will create a long-form answer.
The team also created a graphical interface to their text-based web browser environment. This allows users to add annotations and compare ratings to further enhance the model’s understanding of the questions.
The team refined GPT-3 models for sizes 760M, 13B, and 175B. They used four main training methods; behaviour cloning (BC), reinforcement learning(RL), reinforcement modeling (RM), and rejection sampling. They evaluated the WebGPT proposal using questions from the ELI5 subreddit. Human evaluators made their judgments based upon the criteria that answers should be pertinent, coherent, and supported with trustworthy references.
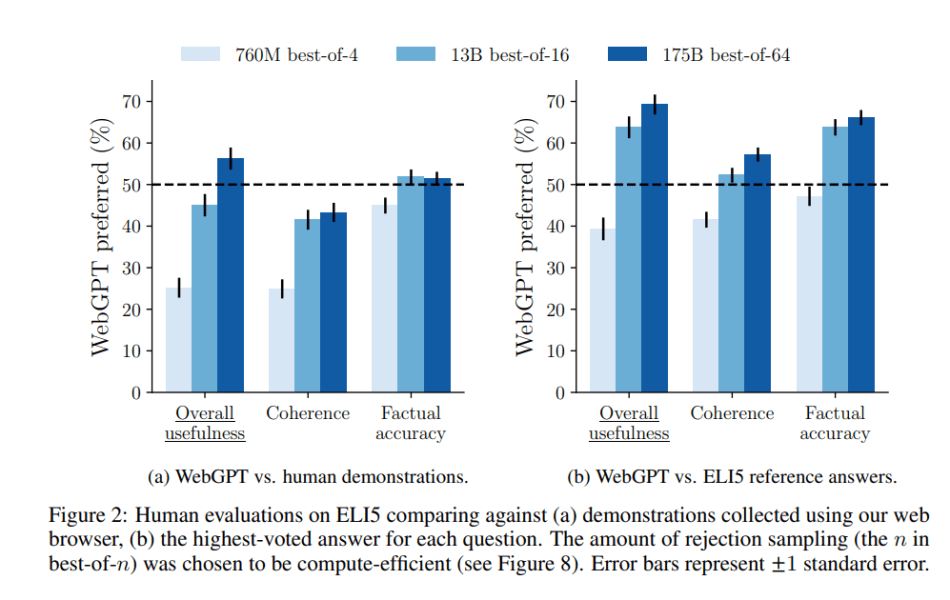
The 175B best of-64 WebGPT model answers were preferred to human demonstrators 56 percent of time, and the reference answers from ELI5 dataset 69% of the times.
Overall, the research shows that a well-tuned pre-trained language model leveraging a text based web-browsing platform can achieve high answer quality for LFQA tasks. This includes outperforming humans using the ELI5 dataset.
The paper WebGPT: Browser-assisted question-answering with Human Feedback It is on OpenAI.com.
Author| Editor: Michael Sarazen

We know you don’t want any news or research breakthroughs to be missed. Subscribe to our popular newsletter Synced Weekly AI Weekly to get weekly AI updates.

{kind=link}